
Over the years, I have enjoyed using the different data dumpers that Perl5 offers. From the basic Data::Dumper to modules dumping in hexadecimal, JSON, with colors, handling closures, with a GUI, as graphs via dot and many other that fellow module developers have posted on CPAN (https://metacpan.org/search?q=data+dump&search_type=modules).
I always find things easier to understand when I can see data and relationships. The funkiest display belonging to ddd (https://www.gnu.org/software/ddd/) that I happen to fire up now and then just for the fun (in the example showing C data but it works as well with the Perl debugger).

Many dumpers are geared towards data transformation and data transmission/storage. A few modules specialize in generating output for the end user to read; I have worked on system that generated hundreds of thousands lines of output and it is close to impossible to read dumps generated by, say, Data::Dumper.
When I started using Perl6, I immediately felt the need to dump data structures (mainly because my noob code wasn’t doing what I expected it to do); This led me to port my Perl5 module (https://metacpan.org/pod/Data::TreeDumper https://github.com/nkh/P6-Data-Dump-Tree) to Perl6. I am now also thinking about porting my HexDump module. I recommend warmly learning Perl6 by porting your modules (if you have any on CPAN), it’s fun, educative, useful for the Perl6 community, and your modules implement a need in a domain that you master leaving you time to concentrate on the Perl6.
My Perl5 module was ripe for a re-write and I wanted to see if and how it would be better if written in Perl6, I was not disappointed.
Perl6 is a big language, it takes time to get the pieces right, for a beginner it may seem daunting, even if one has years of experience, the secret is to take it easy, not give up and listen. Porting a module is the perfect exercise, you can take it easy because you have already done it before, you’re not going to give up because you know you can do it, and you have time to listen to people that have more experience (they also need your work), the Perl6 community has been examplary, helpful, patient, supportive and always present; if you haven visited #perl6 irc channel yet, now is a good time.
.perl
Every object in Perl6 has a ‘perl’ method, it can be used to dump the object and objects under it. The official documentation (https://docs.perl6.org/language/5to6-nutshell#Data%3A%3ADumper) provides a good example.
.gist
Every object also inherits a ‘gist’ method from Mu, the official documentation (https://docs.perl6.org/routine/gist#(Mu)_routine_gist) states: “Returns a string representation of the invocant, optimized for fast recognition by humans.”
dd, the micro dumper
It took me a while to discover this one, I saw that in a post on IRC. You know how it feel when you discover something simple after typing .perl and .gist a few hundred times, bahhh!
https://docs.perl6.org/routine/dd
The three dumpers above are built-in. They are also the fastest way to dump data but as much as their output is welcome, I know that it is possible to present data in a more legible way.
Enter Data::Dump
You can find the module on https://modules.perl6.org/ where all the Perl6 modules are. Perl6 modules link to repositories, Data::Dump source is on https://github.com/tony-o/perl6-data-dump.
Data::dump introduces color, depth limitation, and type specific dumps. The code is a compact hundred lines that is quite easy to understand. This module was quite helpful for a few cases that I had. It also dumps all the methods associated with objects. Unfortunately, it did fail on a few types of objects. Give it a try.
Data::Dump::Tree
Emboldened by the Perl6 community, the fact that I really needed a Dumper for visualization, and the experience from my Perl5 module (mainly the things that I wanted to be done differently) I started working on the module. I had some difficulties at the beginning, I knew nothing about the details of Perl6 and even if there is a resemblance with Perl5, it’s another beast. But I love it, it’s advanced, clean, and well designed, I am grateful for all the efforts that where invested in Perl6.
P6 vs P5 implementation
It’s less than half the size and does as much, which makes it clearer (as much as my newbie code can be considered clean). The old code was one monolithic module with a few long functions, the new code has a better organisation and some functionality was split out to extra modules. It may sound like bit-rot (and it probably is a little) but writing the new code in Perl6 made the changes possible, multi dispatch, traits and other built-in mechanism greatly facilitate the re-factoring.
What does it do that the other modules don’t?
I’ll only talk about a few points here and refer you to the documentation for all the details (https://raw.githubusercontent.com/nkh/P6-Data-Dump-Tree/master/lib/Data/Dump/Tree.pod); also have a look at the examples in the distribution.
The main goal for Data::Dump::Tree is readability, that is achieved with filter, type specific dumpers, colors, and dumper specialization via traits. In the examples directory, you can find JSON_parsed.pl which parses 20 lines of JSON by JSON::Tiny(https://github.com/moritz/json),. I’ll use it as an example below. The parsed data is dumped with .perl, .gist , Data::Dump, and Data::Dump::Tree
.perl output (500 lines, unusable for any average human, Gods can manage)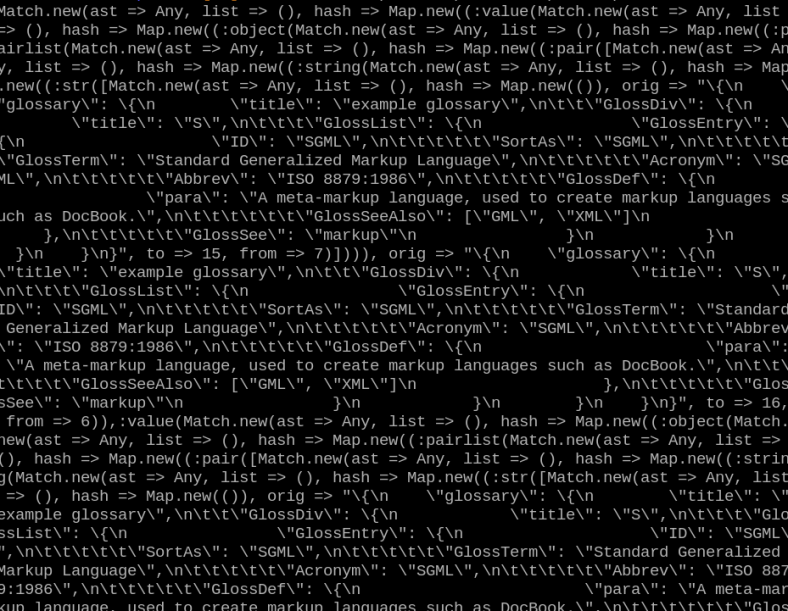
.gist (400 lines, quite readable, no color and long lines limit the readability a bit). Also note that it looks better here than on my terminal who has problems handling unicode properly.
Data::Dump (4200 lines!, removing the methods would probably make it usable)
The methods dump does not help.
Data::Dump::Tree (100 lines, and you are the judge for readability as I am biased). Of course, Data::Dump::Tree is designed for this specific usage, first it understands Match objects, second it can display only part of the string that are matched, which greatly reduces the noise.

Tweeking output
The options are explained in the documentation but here is a little list
– Defining type specific dumper

– filtering to remove data or add a representation for a data set; below the data structure is dumped as it is and then filtered (a filter that shows what it is doing).
As filtering happens on the “header” and “footer” is should be easy to make a HTML/DHTML plugin; Althoug bcat (https://rtomayko.github.io/bcat/), when using ASCII glyphs, works fine.
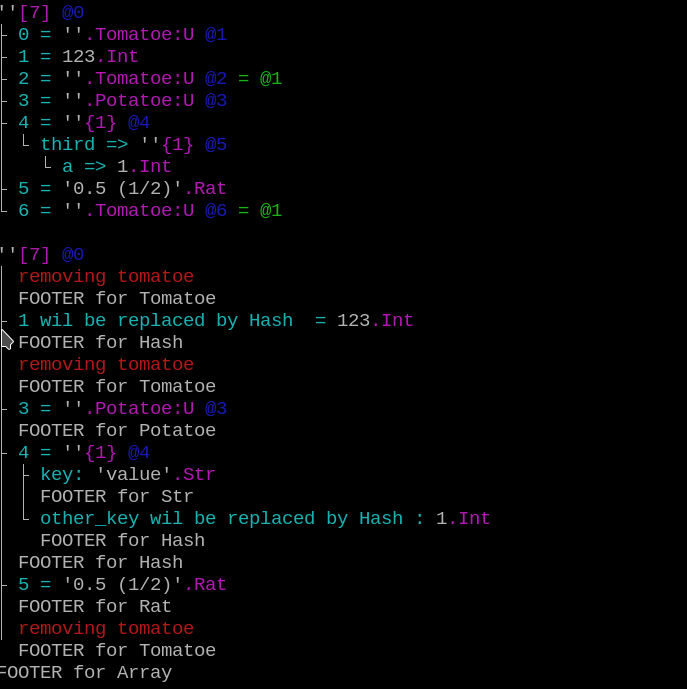
– set the display colors
– change the glyphs
– display address information or not
– use subscripts for indexes
– use ASCII, ANSI, or unicode for the glyphs
Diffs
I tried to implement a diff display with the Perl5 module but failed miserably as it needed architectural changes, The Perl6 version was much easier, in fact, it’s an add-on, a trait, that synchronizes two data dumps. This could be used in tests to show differences between expected and gotten data.

Of course we can eliminate the extra glyphs and the data that is equivalent (I also changed the glyph types to ASCII)
From here
Above anything else, I hope many authors will start writing Perl6 modules. And I also hope to see other data dumping modules. As for Data::Dump::Tree, as it gathers more users, I hope to get requests for change, patches, and error reports.

I use meld (http://meldmerge.org/)
In my failing tests where is-deeply() dumps a huge mess, I replace it with a call to meld:
use Data::Dump;
use File::Temp;
sub meld($a, $b, $description?) is export
{
my ($filename1, $filehandle1) = tempfile;
my ($filename2, $filehandle2) = tempfile;
$filename1.IO.spurt(Dump($a, :!color, :skip-methods, :max-recursion(10)));
$filename2.IO.spurt(Dump($b, :!color, :skip-methods, :max-recursion(10)));
run ‘meld’, $filename1, $filename2;
}
I’ll check out Tree.
I’m surprised to find `dd` documented as just another routine…
It’s actually a Rakudo-specific internal helper function and not standard Perl 6, which is why for some time we did not want to document it at all, and recently agreed to document it as a Rakudo-specific feature….
I moved the docs for `dd`. The new URL is https://docs.perl6.org/programs/01-debugging#index-entry-dd
Thank you for the clarification :)