
Introduction
Hello, everyone!
Today, let me introduce how to mine Wikipedia Infobox with Perl 6.
Wikipedia Infobox plays a very important role in Natural Language Processing, and there are many applications that leverage Wikipedia Infobox:
- Building a Knowlege Base (e.g. DBpedia [0])
- Ranking the importance of attributes [1]
- Question Answering [2]
Among them, I’ll focus on the infobox extraction issues and demonstrate how to parse the sophisticated structures of the infoboxes with Grammar and Actions.
Are Grammar and Actions difficult to learn?
No, they aren’t!
You only need to know just five things:
- Grammar
- token is the most basic one. You may normally use it.
- rule makes whitespace significant.
- regex makes match engine backtrackable.
- Actions
- make prepares an object to return when made calls on it.
- made calls on its invocant and returns the prepared object.
For more info, see: https://docs.perl6.org/language/grammars
What is Infobox?
Have you ever heard the word “Infobox”?
For those who haven’t heard it, I’ll explain it briefly.
An easy way to understand Infobox is by using a real example:
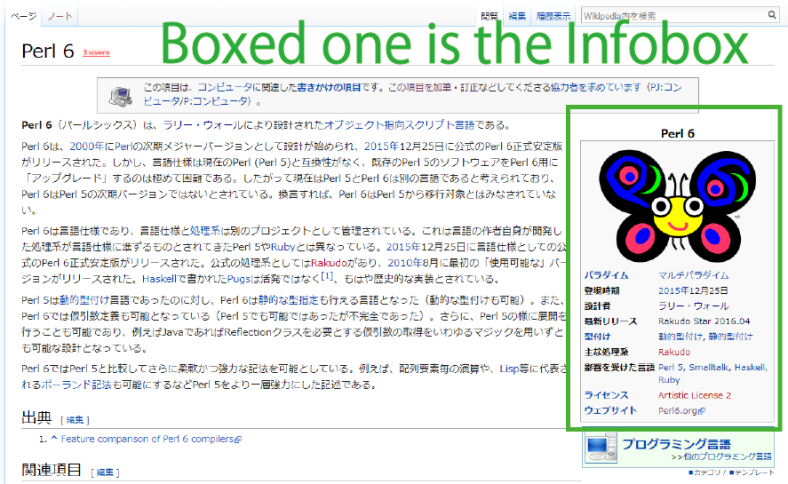
As you can see, the infobox displays the attribute-value pairs of the page’s subject at the top-right side of the page. For example, in this one, it says the designer (ja: 設計者) of Perl 6 is Larry Wall (ja: ラリー・ウォール).
For more info, see: https://en.wikipedia.org/wiki/Help:Infobox
First Example: Perl 6
Firstly to say, I’ll demonstrate the parsing techniques using Japanese Wikipedia not with English Wikipedia.
The main reason is that parsing Japanese Wikipedia is my $dayjob :)
The second reason is that I want to show how easily Perl 6 can handle Unicode strings.
Then, let’s start parsing the infobox in the Perl 6 article!
The code of the article written in wiki markup is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {{Comp-stub}} | |
| {{Infobox プログラミング言語 | |
| |名前 = Perl 6 | |
| |ロゴ = [[Image:Camelia.svg|250px]] | |
| |パラダイム = [[マルチパラダイムプログラミング言語|マルチパラダイム]] | |
| |登場時期 = [[2015年]]12月25日 | |
| |設計者 = [[ラリー・ウォール]] | |
| |最新リリース = Rakudo Star 2016.04 | |
| |型付け = [[動的型付け]], [[静的型付け]] | |
| |処理系 = [[Rakudo]] | |
| |影響を受けた言語 = [[Perl|Perl 5]], [[Smalltalk]], [[Haskell]], [[Ruby]] | |
| |ライセンス = [[Artistic License 2]] | |
| |ウェブサイト = [https://perl6.org/ Perl6.org] | |
| }} | |
| {{プログラミング言語}} | |
| '''Perl 6'''(パールシックス)は、[[ラリー・ウォール]]により設計された[[オブジェクト指向]][[スクリプト言語]]である。 | |
| Perl 6は、[[2000年]]に[[Perl]]の次期メジャーバージョンとして設計が始められ、[[2015年]]12月25日に公式のPerl 6正式安定版がリリースされた。しかし、言語仕様は現在のPerl (Perl 5)と互換性がなく、既存のPerl 5のソフトウェアをPerl 6用に「アップグレ | |
| ード」するのは極めて困難である。したがって現在はPerl 5とPerl 6は別の言語であると考えられており、Perl 6はPerl 5の次期バージョンではないとされている。換言すれば、Perl 6はPerl 5から移行対象とはみなされていない。 |
There are three problematic portions of the code:
- There are superfluous elements after the infobox block, such as the template
{{プログラミング言語}}and the lead sentence starting with'''Perl 6'''. - We have to discriminate three types of tokens: anchor text (e.g.
[[Rakudo]]), raw text (e.g.Rakudo Star 2016.04), weblink (e.g.[https://perl6.org/ Perl6.org]). - The infobox doesn’t start at the top position of the article. In this example,
{{Comb-stub}}is at the top of the article.
OK, then I’ll show how to solve the above problems in the order of Grammar, Actions, Caller (i.e. The portions of the code that calls Grammar and Actions).
Grammar
The code for Grammar is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| grammar Infobox::Grammar { | |
| token TOP { <infobox> .+ } # (#1) | |
| token infobox { '{{Infobox' <.ws> <name> \n <propertylist> '}}' } | |
| token name { <-[\n]>+ } | |
| token propertylist { | |
| [ | |
| | <property> \n | |
| | \n | |
| ]+ | |
| } | |
| token property { | |
| '|' <key=.key-content> '=' <value=.value-content-list> | |
| } | |
| token key-content { <-[=\n]>+ } | |
| token value-content-list { | |
| <value-content>+ | |
| } | |
| token value-content { # (#6) | |
| [ | |
| | <anchortext> | |
| | <weblink> | |
| | <rawtext> | |
| | <delimiter> | |
| ]+ | |
| } | |
| token anchortext { '[[' <-[\n]>+? ']]' } # (#2) | |
| token weblink { '[' <-[\n]>+? ']' } # (#3) | |
| token rawtext { <-[\|\[\]\n、\,\<\>\}\{]>+ } # (#4) | |
| token delimiter { [ '、' | ',' ] } # (#5) | |
| } |
- Solutions to the problem 1:
- Use
.+to match superfluous portions. (#1)
- Use
- Solutions to the problem 2:
- Prepare three types of tokens: anchortext (#2), weblink (#3), and rawtext (#4).
- The tokens may be separated by delimiter (e.g.
,), so prepare the token delimiter. (#5)
- The tokens may be separated by delimiter (e.g.
- Represent the token value-content as an arbitrary length sequence of the four tokens (i.e. anchortext, weblink, rawtext, delimiter). (#6)
- Prepare three types of tokens: anchortext (#2), weblink (#3), and rawtext (#4).
- Solutions to the problem 3:
- There are no particular things to mention.
Actions
The code for Actions is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class Infobox::Actions { | |
| method TOP($/) { make $<infobox>.made } | |
| method infobox($/) { | |
| make %( name => $<name>.made, propertylist => $<propertylist>.made ) | |
| } | |
| method name($/) { make ~$/.trim } | |
| method propertylist($/) { | |
| make $<property>>>.made | |
| } | |
| method property($/) { | |
| make $<key>.made => $<value>.made | |
| } | |
| method key-content($/) { make $/.trim } | |
| method value-content-list($/) { | |
| make $<value-content>>>.made | |
| } | |
| method value-content($/) { # (#1) | |
| my $rawtext = $<rawtext>>>.made>>.trim.grep({ $_ ne "" }); | |
| make %( | |
| anchortext => $<anchortext>>>.made, | |
| weblink => $<weblink>>>.made, | |
| rawtext => $rawtext.elems == 0 ?? $[] !! $rawtext.Array | |
| ); | |
| } | |
| method anchortext($/) { | |
| make ~$/; | |
| } | |
| method weblink($/) { | |
| make ~$/; | |
| } | |
| method rawtext($/) { | |
| make ~$/; | |
| } | |
| } |
- Solutions to the problem 2:
- Make the token value-content consist of the three keys: anchortext, weblink, and rawtext.
- Solutions to the problem 1 and 3:
- There are no particular things to mention.
Caller
The code for Caller is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| my @lines = $*IN.lines; | |
| while @lines { | |
| my $chunk = @lines.join("\n"); # (#1) | |
| my $result = Infobox::Grammar.parse($chunk, actions => Infobox::Actions).made; # (#2) | |
| if $result<name>:exists { | |
| $result<name>.say; | |
| for @($result<propertylist>) -> (:$key, :value($content-list)) { # (#3) | |
| $key.say; | |
| for @($content-list) -> $content { | |
| $content.say; | |
| } | |
| } | |
| } | |
| shift @lines; | |
| } |
- Solutions to the problem 3:
- Read the article line-by-line and make a chunk which contains the lines between the current line and the last line. (#1)
- If the parser determines that:
- The chunk doesn’t contain the infobox, it returns an undefined value. One of the good ways to receive an undefined value is to use
$sigil. (#2) - The chunk contains the infobox, it returns a defined value. Use
@()contextualizer and iterate the result. (#3)
- The chunk doesn’t contain the infobox, it returns an undefined value. One of the good ways to receive an undefined value is to use
- Solutions to the problem 1 and 2:
- There are no particular things to mention.
Running the Parser
Are you ready?
It’s time to run the 1st example!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| $ perl6 parser.p6 < perl6.txt | |
| プログラミング言語 | |
| 名前 | |
| {anchortext => [], rawtext => [Perl 6], weblink => []} | |
| ロゴ | |
| {anchortext => [[[Image:Camelia.svg|250px]]], rawtext => [], weblink => []} | |
| パラダイム | |
| {anchortext => [[[マルチパラダイムプログラミング言語|マルチパラダイム]]], rawtext => [], weblink => []} | |
| 登場時期 | |
| {anchortext => [[[2015年]]], rawtext => [12月25日], weblink => []} | |
| 設計者 | |
| {anchortext => [[[ラリー・ウォール]]], rawtext => [], weblink => []} | |
| 最新リリース | |
| {anchortext => [], rawtext => [Rakudo Star 2016.04], weblink => []} | |
| 型付け | |
| {anchortext => [[[動的型付け]] [[静的型付け]]], rawtext => [], weblink => []} | |
| 処理系 | |
| {anchortext => [[[Rakudo]]], rawtext => [], weblink => []} | |
| 影響を受けた言語 | |
| {anchortext => [[[Perl|Perl 5]] [[Smalltalk]] [[Haskell]] [[Ruby]]], rawtext => [], weblink => []} | |
| ライセンス | |
| {anchortext => [[[Artistic License 2]]], rawtext => [], weblink => []} | |
| ウェブサイト | |
| {anchortext => [], rawtext => [], weblink => [[https://perl6.org/ Perl6.org]]} |
The example we have seen may be too easy for you. Let’s challenge more harder one!
Second Example: Albert Einstein
As the second example, let’s parse the infobox of Albert Einstein.
The code of the article written in wiki markup is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {{Infobox Scientist | |
| |name = アルベルト・アインシュタイン | |
| |image = Einstein1921 by F Schmutzer 2.jpg | |
| |caption = [[1921年]]、[[ウィーン]]での[[講義]]中 | |
| |birth_date = {{生年月日と年齢|1879|3|14|no}} | |
| |birth_place = {{DEU1871}}<br>[[ヴュルテンベルク王国]][[ウルム]] | |
| |death_date = {{死亡年月日と没年齢|1879|3|14|1955|4|18}} | |
| |death_place = {{USA1912}}<br />[[ニュージャージー州]][[プリンストン (ニュージャージー州)|プリンストン]] | |
| |residence = {{DEU}}<br />{{ITA}}<br>{{CHE}}<br />{{AUT}}(現在の[[チェコ]])<br />{{BEL}}<br />{{USA}} | |
| |nationality = {{DEU1871}}、ヴュルテンベルク王国(1879-96)<br />[[無国籍]](1896-1901)<br />{{CHE}}(1901-55)<br />{{AUT1867}}(1911-12)<br />{{DEU1871}}、{{DEU1919}}(1914-33)<br />{{USA1912}}(1940-55) | |
| | spouse = [[ミレヴァ・マリッチ]] (1903-1919)<br />{{nowrap|{{仮リンク|エルザ・アインシュタイン|en|Elsa Einstein|label=エルザ・レーベンタール}} (1919-1936)}} | |
| | children = [[リーゼル・アインシュタイン|リーゼル]] (1902-1903?)<br />[[ハンス・アルベルト・アインシュタイン|ハンス | |
| ・アルベルト]] (1904-1973)<br />[[エドゥアルト・アインシュタイン|エドゥアルト]] (1910-1965) | |
| |field = [[物理学]]<br />[[哲学]] | |
| |work_institution = {{Plainlist| | |
| * [[スイス特許庁]] ([[ベルン]]) (1902-1909) | |
| * {{仮リンク|ベルン大学|en|University of Bern}} (1908-1909) | |
| * [[チューリッヒ大学]] (1909-1911) | |
| * [[プラハ・カレル大学]] (1911-1912) | |
| * [[チューリッヒ工科大学]] (1912-1914) | |
| * [[プロイセン科学アカデミー]] (1914-1933) | |
| * [[フンボルト大学ベルリン]] (1914-1917) | |
| * {{仮リンク|カイザー・ヴィルヘルム協会|en|Kaiser Wilhelm Society|label=カイザー・ヴィルヘルム研究所}} (化学・物理学研究所長, 1917-1933) | |
| * [[ドイツ物理学会]] (会長, 1916-1918) | |
| * [[ライデン大学]] (客員, 1920-) | |
| * [[プリンストン高等研究所]] (1933-1955) | |
| * [[カリフォルニア工科大学]] (客員, 1931-33) | |
| }} | |
| |alma_mater = [[チューリッヒ工科大学]]<br />[[チューリッヒ大学]] | |
| |doctoral_advisor = {{仮リンク|アルフレート・クライナー|en|Alfred Kleiner}} | |
| |academic_advisors = {{仮リンク|ハインリヒ・フリードリヒ・ウェーバー|en|Heinrich Friedrich Weber}} | |
| |doctoral_students = | |
| |known_for = {{Plainlist| | |
| *[[一般相対性理論]] | |
| *[[特殊相対性理論]] | |
| *[[光電効果]] | |
| *[[ブラウン運動]] | |
| *[[E=mc2|質量とエネルギーの等価性]](E=mc<sup>2</sup>) | |
| *[[アインシュタイン方程式]] | |
| *[[ボース分布関数]] | |
| *[[宇宙定数]] | |
| *[[ボース=アインシュタイン凝縮]] | |
| *[[EPRパラドックス]] | |
| *{{仮リンク|古典統一場論|en|Classical unified field theories}} | |
| }} | |
| | influenced = {{Plainlist| | |
| * {{仮リンク|エルンスト・G・シュトラウス|en|Ernst G. Straus}} | |
| * [[ネイサン・ローゼン]] | |
| * [[レオ・シラード]] | |
| }} | |
| |prizes = {{Plainlist| | |
| *{{仮リンク|バーナード・メダル|en|Barnard Medal for Meritorious Service to Science}}(1920) | |
| *[[ノーベル物理学賞]](1921) | |
| *[[マテウチ・メダル]](1921) | |
| *[[コプリ・メダル]](1925) | |
| *[[王立天文学会ゴールドメダル]](1926) | |
| *[[マックス・プランク・メダル]](1929) | |
| }} | |
| |religion = | |
| |signature = Albert Einstein signature 1934.svg | |
| |footnotes = | |
| }} | |
| {{thumbnail:begin}} | |
| {{thumbnail:ノーベル賞受賞者|1921年|ノーベル物理学賞|光電効果の法則の発見等}} | |
| {{thumbnail:end}} | |
| '''アルベルト・アインシュタイン'''<ref group="†">[[日本語]]における表記には、他に「アル{{Underline|バー}}ト・アインシュine|バー}}ト・アイン{{Underline|ス}}タイン」([[英語]]の発音由来)がある。</ref>({{lang-de-short|Albert Einstein}}<ref ɛrt ˈaɪnˌʃtaɪn}} '''ア'''ルベルト・'''ア'''インシュタイン、'''ア'''ルバート・'''ア'''インシュタイン</ref><ref group="†"taɪn}} '''ア'''ルバ(ー)ト・'''ア'''インスタイン、'''ア'''ルバ(ー)'''タ'''インスタイン</ref><ref>[http://dictionary.rein Einstein] (Dictionary.com)</ref><ref>[http://www.oxfordlearnersdictionaries.com/definition/english/albert-einstein?q=Albert+Einstein Albert Einstein] (Oxford Learner's Dictionaries)</ref>、[[1879年]][[3月14日]] – [[1955年]][[4月18日]])ツ]]生まれの[[理論物理学者]]である。 |
As you can see, there are five new problems here:
- Some of the templates
- contain newlines; and
- are nesting (e.g.
{{nowrap|{{仮リンク|...}}...}})
- Some of the attribute-value pairs are empty.
- Some of the value-sides of the attribute-value pairs
- contain break tag; and
- consist of different types of the tokens (e.g. anchortext and rawtext).
So you need to add positional information to represent the dependency between tokens.
I’ll show how to solve the above problems in the order of Grammar, Actions.
The code of the Caller is the same as the previous one.
Grammar
The code for Grammar is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| grammar Infobox::Grammar { | |
| token TOP { <infobox> .+ } | |
| token infobox { '{{Infobox' <.ws> <name> \n <propertylist> '}}' } | |
| token name { <-[\n]>+ } | |
| token propertylist { | |
| [ | |
| | <property> \n | |
| | \n | |
| ]+ | |
| } | |
| token property { | |
| [ | |
| | '|' <key=.key-content> '=' <value=.value-content-list> | |
| | '|' <key=.key-content> '=' # (#4) | |
| ] | |
| } | |
| token key-content { <-[=\n]>+ } | |
| token value-content-list { | |
| [ | |
| | <value-content> <br> # (#6) | |
| | <value-content> | |
| | <br> | |
| ]+ | |
| } | |
| token value-content-list-nl { # (#1) | |
| [ | |
| | <value-content> <br> # (#7) | |
| | <value-content> | |
| | <br> | |
| ]+ % \n | |
| } | |
| token value-content { | |
| [ | |
| | <anchortext> | |
| | <weblink> | |
| | <rawtext> | |
| | <template> | |
| | <delimiter> | |
| | <sup> | |
| ]+ | |
| } | |
| token br { # (#5) | |
| [ | |
| | '<br />' | |
| | '<br/>' | |
| | '<br>' | |
| ] | |
| } | |
| token template { | |
| [ | |
| | '{{' <-[\n]>+? '}}' | |
| | '{{nowrap' '|' <value-content-list> '}}' # (#3) | |
| | '{{Plainlist' '|' \n <value-content-list-nl> \n '}}' # (#2) | |
| ] | |
| } | |
| token anchortext { '[[' <-[\n]>+? ']]' } | |
| token weblink { '[' <-[\n]>+? ']' } | |
| token rawtext { <-[\|\[\]\n、\,\<\>\}\{]>+ } | |
| token delimiter { [ '、' | ',' | ' ' ] } | |
| token sup { '<sup>' <-[\n]>+? '</sup>'} | |
| } |
- Solutions to the problem 1.1:
- Create the token value-content-list-nl which is the newline separated version of the token value-content-list. It is useful to use modified quantifier
%to represent this kind of sequence. (#1) - Create the token template. In this one, define a sequence that represents Plainlist template. (#2)
- Create the token value-content-list-nl which is the newline separated version of the token value-content-list. It is useful to use modified quantifier
- Solutions to the problem 1.2:
- Make the token template enable to call the token value-content-list. This modification triggers recursive call and captures nesting structure, because the token value-content-list contains the token template. (#3)
- Solutions to the problem 2:
- In the token property, define a sequence that value-side is empty (i.e. a sequence that ends with ‘=’). (#4)
- Solutions to the problem 3.1:
- Create the token br (#5)
- Let the token br follow the token value-content in the two tokens:
- The token value-content-list (#6)
- The token value-content-list-nl (#7)
Actions
The code for Actions is:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class Infobox::Actions { | |
| method TOP($/) { make $<infobox>.made } | |
| method infobox($/) { | |
| make %( name => $<name>.made, propertylist => $<propertylist>.made ) | |
| } | |
| method name($/) { make $/.trim } | |
| method propertylist($/) { | |
| make $<property>>>.made | |
| } | |
| method property($/) { | |
| make $<key>.made => $<value>.made | |
| } | |
| method key-content($/) { make $/.trim } | |
| method value-content-list($/) { | |
| make $<value-content>>>.made | |
| } | |
| method value-content($/) { | |
| my $rawtext = $<rawtext>>>.made>>.trim.grep({ $_ ne "" }); | |
| make %( | |
| anchortext => $<anchortext>>>.made, | |
| weblink => $<weblink>>>.made, | |
| rawtext => $rawtext.elems == 0 ?? $[] !! $rawtext.Array, | |
| template => $<template>>>.made; | |
| ); | |
| } | |
| method template($/) { | |
| make %(body => ~$/, from => $/.from, to => $/.to); # (#1) | |
| } | |
| method anchortext($/) { | |
| make %(body => ~$/, from => $/.from, to => $/.to); # (#2) | |
| } | |
| method weblink($/) { | |
| make %(body => ~$/, from => $/.from, to => $/.to); # (#3) | |
| } | |
| method rawtext($/) { | |
| make %(body => ~$/, from => $/.from, to => $/.to); # (#4) | |
| } | |
| } |
- Solutions to the problem 3.2:
- Use Match.from and Match.to to get the match starting position and the match ending position respectively when calling make. (#1 ~ #4)
Running the Parser
It’s time to run!
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| $ perl6 parser.p6 < einstein.txt | |
| Scientist | |
| name | |
| {anchortext => [], rawtext => [{body => アルベルト・アインシュタイン, from => 27, to => 42}], template => [], weblink => []} | |
| image | |
| {anchortext => [], rawtext => [{body => Einstein1921 by F Schmutzer 2.jpg, from => 51, to => 85}], template => [], weblink => []} | |
| caption | |
| {anchortext => [{body => [[1921年]], from => 97, to => 106} {body => [[ウィーン]], from => 107, to => 115} {body => [[講義]], from => 117, to => 123}], rawtext => [{body => , from => 96, to => 97} {body => での, from => 115, to => 117} {body => 中, from => 123, to => 124}], template => [], weblink => []} | |
| birth_date | |
| {anchortext => [], rawtext => [{body => , from => 138, to => 139}], template => [{body => {{生年月日と年齢|1879|3|14|no}}, from => 139, to => 163}], weblink => []} | |
| birth_place | |
| {anchortext => [], rawtext => [{body => , from => 178, to => 179}], template => [{body => {{DEU1871}}, from => 179, to => 190}], weblink => []} | |
| {anchortext => [{body => [[ヴュルテンベルク王国]], from => 194, to => 208} {body => [[ウルム]], from => 208, to => 215}], rawtext => [], template => [], weblink => []} | |
| death_date | |
| {anchortext => [], rawtext => [{body => , from => 229, to => 230}], template => [{body => {{死亡年月日と没年齢|1879|3|14|1955|4|18}}, from => 230, to => 263}], weblink => []} | |
| death_place | |
| {anchortext => [], rawtext => [{body => , from => 278, to => 279}], template => [{body => {{USA1912}}, from => 279, to => 290}], weblink => []} | |
| {anchortext => [{body => [[ニュージャージー州]], from => 296, to => 309} {body => [[プリンストン (ニュージャージー州)|プリンストン]], from => 309, to => 338}], rawtext => [], template => [], weblink => []} | |
| residence | |
| {anchortext => [], rawtext => [{body => , from => 351, to => 352}], template => [{body => {{DEU}}, from => 352, to => 359}], weblink => []} | |
| {anchortext => [], rawtext => [], template => [{body => {{ITA}}, from => 365, to => 372}], weblink => []} | |
| {anchortext => [], rawtext => [], template => [{body => {{CHE}}, from => 376, to => 383}], weblink => []} | |
| {anchortext => [{body => [[チェコ]], from => 400, to => 407}], rawtext => [{body => (現在の, from => 396, to => 400} {body => ), from => 407, to => 408}], template => [{body => {{AUT}}, from => 389, to => 396}], weblink => []} | |
| {anchortext => [], rawtext => [], template => [{body => {{BEL}}, from => 414, to => 421}], weblink => []} | |
| {anchortext => [], rawtext => [], template => [{body => {{USA}}, from => 427, to => 434}], weblink => []} | |
| nationality | |
| {anchortext => [], rawtext => [{body => , from => 449, to => 450} {body => ヴュルテンベルク王国(1879-96), from => 462, to => 481}], template => [{body => {{DEU1871}}, from => 450, to => 461}], weblink => []} | |
| {anchortext => [{body => [[無国籍]], from => 487, to => 494}], rawtext => [{body => (1896-1901), from => 494, to => 505}], template => [], weblink => []} | |
| {anchortext => [], rawtext => [{body => (1901-55), from => 518, to => 527}], template => [{body => {{CHE}}, from => 511, to => 518}], weblink => []} | |
| {anchortext => [], rawtext => [{body => (1911-12), from => 544, to => 553}], template => [{body => {{AUT1867}}, from => 533, to => 544}], weblink => []} | |
| {anchortext => [], rawtext => [{body => (1914-33), from => 582, to => 591}], template => [{body => {{DEU1871}}, from => 559, to => 570} {body => {{DEU1919}}, from => 571, to => 582}], weblink => []} | |
| {anchortext => [], rawtext => [{body => (1940-55), from => 608, to => 617}], template => [{body => {{USA1912}}, from => 597, to => 608}], weblink => []} | |
| spouse | |
| {anchortext => [{body => [[ミレヴァ・マリッチ]], from => 634, to => 647}], rawtext => [{body => , from => 633, to => 634} {body => (1903-1919), from => 653, to => 664}], template => [], weblink => []} | |
| {anchortext => [], rawtext => [], template => [{body => {{nowrap|{{仮リンク|エルザ・アインシュタイン|en|Elsa Einstein|label=エルザ・レーベンタール}} (1919-1936)}}, from => 670, to => 754}], weblink => []} | |
| children | |
| {anchortext => [{body => [[リーゼル・アインシュタイン|リーゼル]], from => 771, to => 793}], rawtext => [{body => , from => 770, to => 771} {body => (1902-1903?), from => 793, to => 806}], template => [], weblink => []} | |
| {anchortext => [{body => [[ハンス・アルベルト・アインシュタイン|ハンス・アルベルト]], from => 812, to => 844}], rawtext => [{body => (1904-1973), from => 844, to => 856}], template => [], weblink => []} | |
| {anchortext => [{body => [[エドゥアルト・アインシュタイン|エドゥアルト]], from => 862, to => 888}], rawtext => [{body => (1910-1965), from => 888, to => 900}], template => [], weblink => []} | |
| field | |
| {anchortext => [{body => [[物理学]], from => 910, to => 917}], rawtext => [{body => , from => 909, to => 910}], template => [], weblink => []} | |
| {anchortext => [{body => [[哲学]], from => 923, to => 929}], rawtext => [], template => [], weblink => []} | |
| work_institution | |
| {anchortext => [], rawtext => [{body => , from => 949, to => 950}], template => [{body => {{Plainlist| | |
| * [[スイス特許庁]] ([[ベルン]]) (1902-1909) | |
| * {{仮リンク|ベルン大学|en|University of Bern}} (1908-1909) | |
| * [[チューリッヒ大学]] (1909-1911) | |
| * [[プラハ・カレル大学]] (1911-1912) | |
| * [[チューリッヒ工科大学]] (1912-1914) | |
| * [[プロイセン科学アカデミー]] (1914-1933) | |
| * [[フンボルト大学ベルリン]] (1914-1917) | |
| * {{仮リンク|カイザー・ヴィルヘルム協会|en|Kaiser Wilhelm Society|label=カイザー・ヴィルヘルム研究所}} (化学・物理学研究所長, 1917-1933) | |
| * [[ドイツ物理学会]] (会長, 1916-1918) | |
| * [[ライデン大学]] (客員, 1920-) | |
| * [[プリンストン高等研究所]] (1933-1955) | |
| * [[カリフォルニア工科大学]] (客員, 1931-33) | |
| }}, from => 950, to => 1409}], weblink => []} | |
| alma_mater | |
| {anchortext => [{body => [[チューリッヒ工科大学]], from => 1424, to => 1438}], rawtext => [{body => , from => 1423, to => 1424}], template => [], weblink => []} | |
| {anchortext => [{body => [[チューリッヒ大学]], from => 1444, to => 1456}], rawtext => [], template => [], weblink => []} | |
| doctoral_advisor | |
| {anchortext => [], rawtext => [{body => , from => 1476, to => 1477}], template => [{body => {{仮リンク|アルフレート・ク | |
| ライナー|en|Alfred Kleiner}}, from => 1477, to => 1516}], weblink => []} | |
| academic_advisors | |
| {anchortext => [], rawtext => [{body => , from => 1537, to => 1538}], template => [{body => {{仮リンク|ハインリヒ・フリ | |
| ードリヒ・ウェーバー|en|Heinrich Friedrich Weber}}, from => 1538, to => 1593}], weblink => []} | |
| doctoral_students | |
| Nil | |
| known_for | |
| {anchortext => [], rawtext => [{body => , from => 1627, to => 1628}], template => [{body => {{Plainlist| | |
| *[[一般相対性理論]] | |
| *[[特殊相対性理論]] | |
| *[[光電効果]] | |
| *[[ブラウン運動]] | |
| *[[E=mc2|質量とエネルギーの等価性]](E=mc<sup>2</sup>) | |
| *[[アインシュタイン方程式]] | |
| *[[ボース分布関数]] | |
| *[[宇宙定数]] | |
| *[[ボース=アインシュタイン凝縮]] | |
| *[[EPRパラドックス]] | |
| *{{仮リンク|古典統一場論|en|Classical unified field theories}} | |
| }}, from => 1628, to => 1861}], weblink => []} | |
| influenced | |
| {anchortext => [], rawtext => [{body => , from => 1877, to => 1878}], template => [{body => {{Plainlist| | |
| * {{仮リンク|エルンスト・G・シュトラウス|en|Ernst G. Straus}} | |
| * [[ネイサン・ローゼン]] | |
| * [[レオ・シラード]] | |
| }}, from => 1878, to => 1968}], weblink => []} | |
| prizes | |
| {anchortext => [], rawtext => [{body => , from => 1978, to => 1979}], template => [{body => {{Plainlist| | |
| *{{仮リンク|バーナード・メダル|en|Barnard Medal for Meritorious Service to Science}}(1920) | |
| *[[ノーベル物理学賞]](1921) | |
| *[[マテウチ・メダル]](1921) | |
| *[[コプリ・メダル]](1925) | |
| *[[王立天文学会ゴールドメダル]](1926) | |
| *[[マックス・プランク・メダル]](1929) | |
| }}, from => 1979, to => 2181}], weblink => []} | |
| religion | |
| Nil | |
| signature | |
| {anchortext => [], rawtext => [{body => Albert Einstein signature 1934.svg, from => 2206, to => 2241}], template => [], weblink => []} | |
| footnotes | |
| Nil |
Conclusion
I demonstrated the parsing techniques of the infoboxes. I highly recommend you to create your own parser if you have a chance to use Wikipedia as a resource for NLP. It will deepen your knowledge about not only Perl 6 but also Wikipedia.
See you again!
Citations
[0] Lehmann, Jens, et al. “DBpedia–a large-scale, multilingual knowledge base extracted from Wikipedia.” Semantic Web 6.2 (2015): 167-195.
[1] Ali, Esraa, Annalina Caputo, and Séamus Lawless. “Entity Attribute Ranking Using Learning to Rank.”
[2] Morales, Alvaro, et al. “Learning to answer questions from wikipedia infoboxes.” Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.
License
All of the materials from Wikipedia are licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License.
—
Itsuki Toyota
A web developer in Japan.
